記一次基于倒序索引的SQL優(yōu)化
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
本文測試環(huán)境為SQLserver2019 背景某業(yè)務(wù)流水表,會(huì)基于固定范圍內(nèi)的業(yè)務(wù)編號(hào)做寫入以及查詢操作,熱數(shù)據(jù)的量級(jí)在億級(jí)別,一個(gè)典型的查詢是基于業(yè)務(wù)編碼查詢最新(時(shí)間戳)某種狀態(tài)的前N條數(shù)據(jù)
簡化后的表結(jié)構(gòu)如下
create table TestTable01 ( id bigint identity, --主鍵Id,自增 business_code char(7), --業(yè)務(wù)編碼,一定范圍內(nèi)(測試代碼從BC00001~BC00200) business_timestamp datetime2, --業(yè)務(wù)發(fā)生時(shí)間戳 business_value decimal(15,3), --業(yè)務(wù)發(fā)生時(shí)涉及的數(shù)值 business_status tinyint, --業(yè)務(wù)狀態(tài)編碼(測試數(shù)據(jù)范圍為1~5) other_col varchar(100), constraint pk_TestTable01 primary key(id) ); 基于上述表結(jié)構(gòu),簡化數(shù)據(jù)量,基于時(shí)間順序生成1千萬條數(shù)據(jù) declare @i int = 0 begin tran while @i<10000000 begin insert into TestTable01 values (concat('BC',FORMAT(cast(rand()*200 as int), '00000')),dateadd(ss,@i,'2024-01-01'),rand()*10000,rand()*5,newid()) set @i = @i+1 end commit 典型的數(shù)據(jù)如下
select top 100 * from TestTable01
反向索引掃描的執(zhí)行計(jì)劃除了主鍵索引,開發(fā)人員創(chuàng)建的索引如下
create index idx_bcode_statue on TestTable01 (business_code,business_status) 一個(gè)典型的查詢?nèi)缦拢?span data-wiz-span="data-wiz-span">咋一看確實(shí)沒啥問題
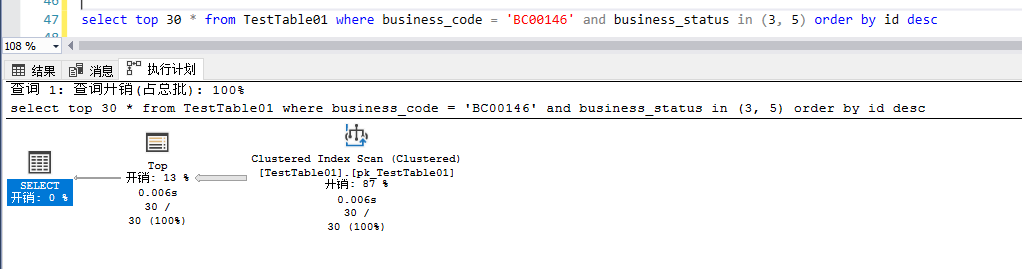
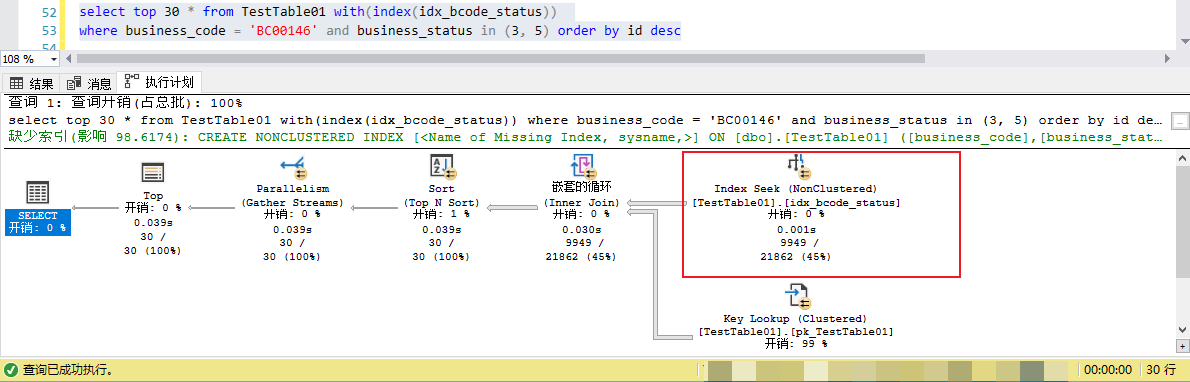
select top 30 * from TestTable01 where business_code = 'BC00146' and business_status in (3, 5) order by id desc 所以一開始基于business_code+business_status建立的索引,表面上看沒有什么不妥當(dāng)?shù)?span data-wiz-span="data-wiz-span">,仔細(xì)觀察一下,還是會(huì)發(fā)現(xiàn)一些潛在問題的端倪
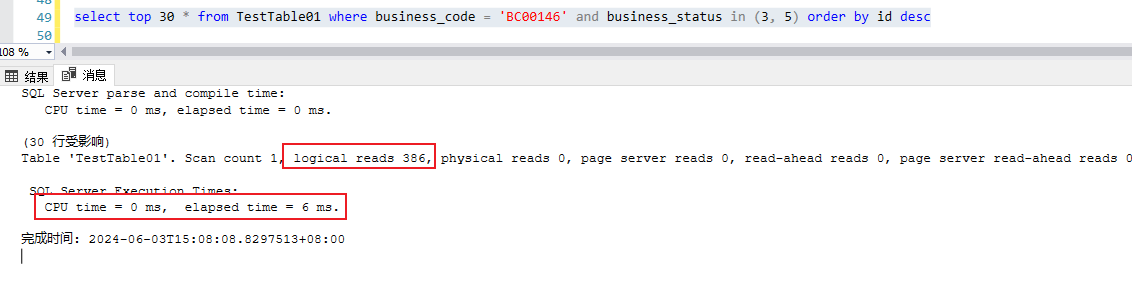
首先看執(zhí)行計(jì)劃,改查執(zhí)行的時(shí)候,并沒有用到idx_bcode_statue這個(gè)索引,盡管這個(gè)索引包含了where條件中的兩個(gè)字段,實(shí)際上執(zhí)行計(jì)劃是一個(gè)cluster index scan,也就是全表掃描,但是該查詢瞬間就返回了,“體感上”很快。
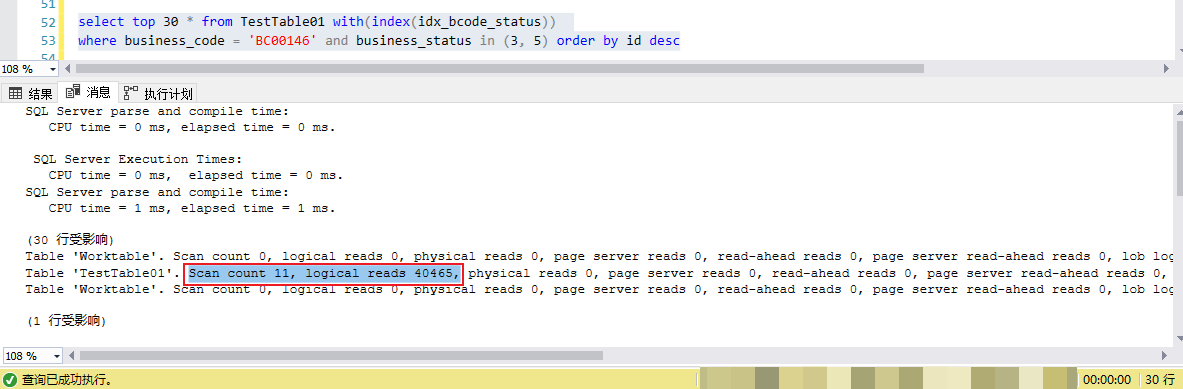
上述查詢IO以及CPU消耗信息,342次IO以及幾乎為0的CPU消耗,,總耗時(shí)6毫秒,這個(gè)代價(jià)確實(shí)不大
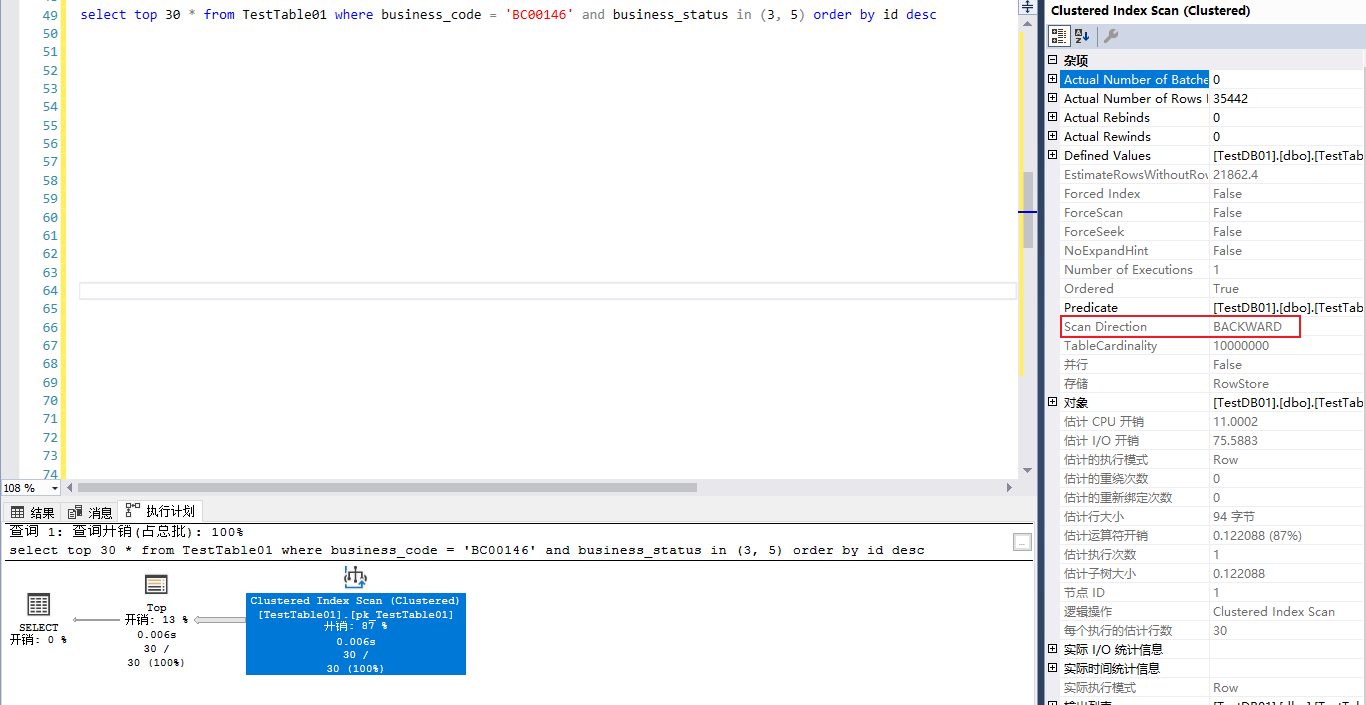
可能有人會(huì)有疑問,這里測試數(shù)據(jù)1000W的數(shù)據(jù)量,全表掃描應(yīng)該是很慢的才對(duì),事實(shí)上不要看到全量掃描就覺得有問題,繼續(xù)看一下該執(zhí)行計(jì)劃的細(xì)節(jié)。 這里的Scan Direction是BACKWARD,也就是“反向(聚集)索引掃描”,他確實(shí)是一個(gè)表掃描,但是掃描過程中提出來符合條件的數(shù)據(jù)之后,掃描中斷,并不會(huì)完整地掃描整個(gè)表的數(shù)據(jù)頁。
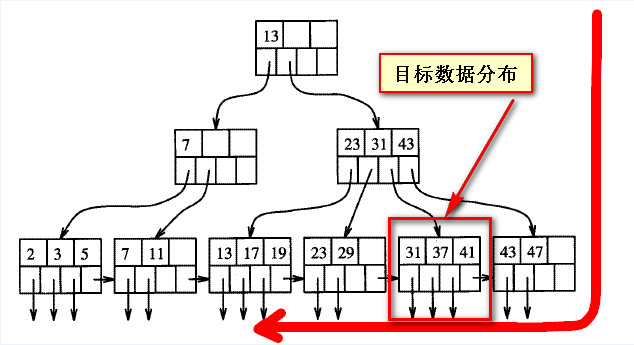
這里不難理解,對(duì)于“聚集索引”這個(gè)B+樹,因?yàn)槭遣樵兡硞€(gè)業(yè)務(wù)代碼的某兩種狀態(tài)最新的30條數(shù)據(jù),按照數(shù)據(jù)的生成邏輯(主鍵值跟隨時(shí)間戳做遞增),所以倒序掃描,絕大多數(shù)情況下可以很快找到符合條件的數(shù)據(jù)。原理如下示意圖。所謂的反向索引掃描,就是從B+樹的右邊開始往左邊掃描數(shù)據(jù)頁,直至找到滿足查詢條件的數(shù)據(jù)。
關(guān)于“正向索引掃描”和反向索引掃描,參考這里:https://www.cnblogs.com/wy123/p/5552719.html
所以,即便是開發(fā)人員基于where查詢條件建立的create index idx_bcode_statue on TestTable01 (business_code,business_status)索引沒有用上,但是這個(gè)查詢?cè)诖蠖鄶?shù)情況下都沒有問題。
上述采用(反向)索引掃描的執(zhí)行計(jì)劃,終究是掃描(scan)而不是查找(seek),如果不想采用默認(rèn)的索引掃描策略,強(qiáng)制使用上述idx_bcode_statue這個(gè)索引呢,代價(jià)會(huì)變高,變低,還是差不多?
可以看到使用了idx_bcode_statue 索引的情況下,執(zhí)行計(jì)劃看起來確實(shí)是索引查找(index seek),但是相比默認(rèn)的聚集索引反向掃描,這里的IO代價(jià)也翻了數(shù)十倍。 這就是為什么優(yōu)化器在默認(rèn)情況下不選擇非聚集索引(idx_bcode_statue)查找的原因,如果明白了這個(gè)道理,其實(shí)就不用往下看了。
因此默認(rèn)情況下,優(yōu)化器選擇執(zhí)行聚集索引(反向)掃描是沒有問題的,不出問題的話,問題就出來了。。。 反向索引掃描造成的IO消耗某天業(yè)務(wù)反饋某生產(chǎn)系統(tǒng)偶發(fā)出現(xiàn)卡頓,嚴(yán)重影響業(yè)務(wù),同時(shí)服務(wù)器上部署的擴(kuò)展事件(Extended Event)也確實(shí)捕獲到了一些關(guān)于該SQL的慢日志,結(jié)合業(yè)務(wù)反饋問題出現(xiàn)的時(shí)間點(diǎn)和擴(kuò)展事件捕獲的慢查詢,確定就是該語句引起的性能問題。
通過分析慢查詢?nèi)罩景l(fā)現(xiàn):這個(gè)SQL在某些參數(shù)下執(zhí)行時(shí)間較長,遠(yuǎn)超預(yù)期,同時(shí)其IO消耗非常大,有超過10W次甚至更多的IO。
但從擴(kuò)展事件里解析出來的SQL語句,包括了參數(shù),當(dāng)嘗試再次去服務(wù)器上執(zhí)行的時(shí)候發(fā)現(xiàn)其執(zhí)行非常快,執(zhí)行計(jì)劃也是預(yù)期的反向聚集索引掃描,IO消耗非常低,那么在當(dāng)時(shí)的情況下,為什么會(huì)出現(xiàn)性能如此的低下,需要消耗如此多的IO?
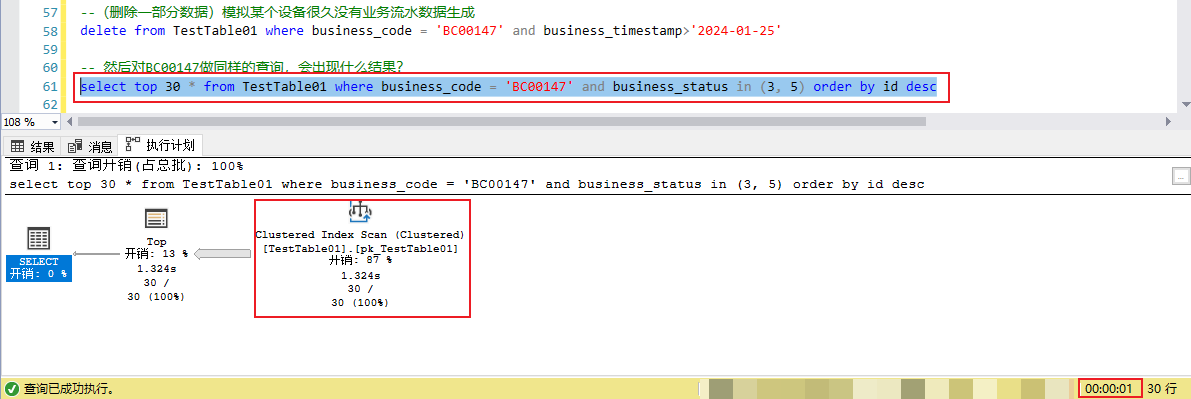
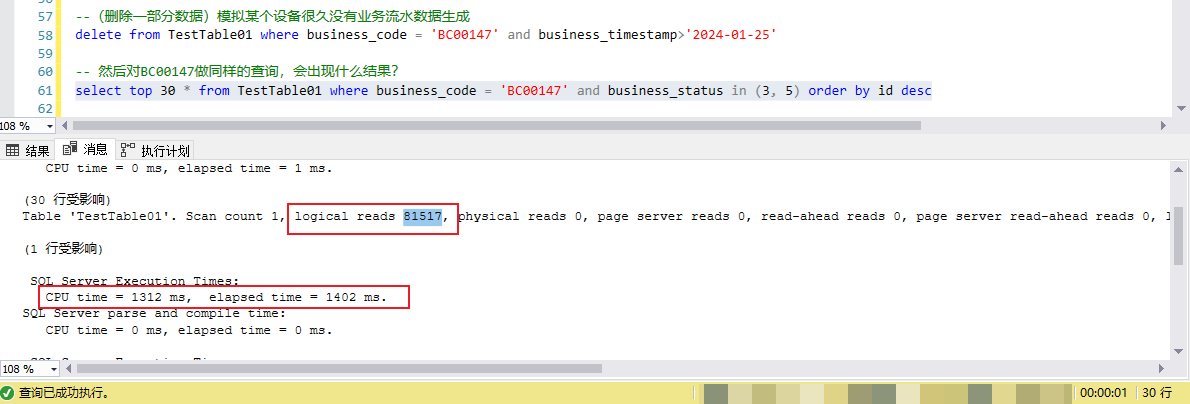
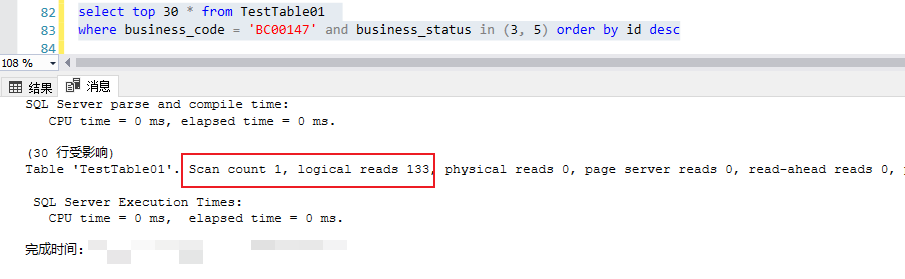
這里(刪除一部分?jǐn)?shù)據(jù))模擬某個(gè)設(shè)備很久沒有業(yè)務(wù)流水?dāng)?shù)據(jù)生成 然后對(duì)這個(gè)Id做類似上述做同樣的查詢,會(huì)出現(xiàn)什么結(jié)果?
對(duì)比上述的測試案例,大約在6毫秒返回結(jié)果,這次的案例就出現(xiàn)在1秒多,IO在80000多次。這明顯跟一開始的case(8毫秒返回結(jié)果)有天壤之別。
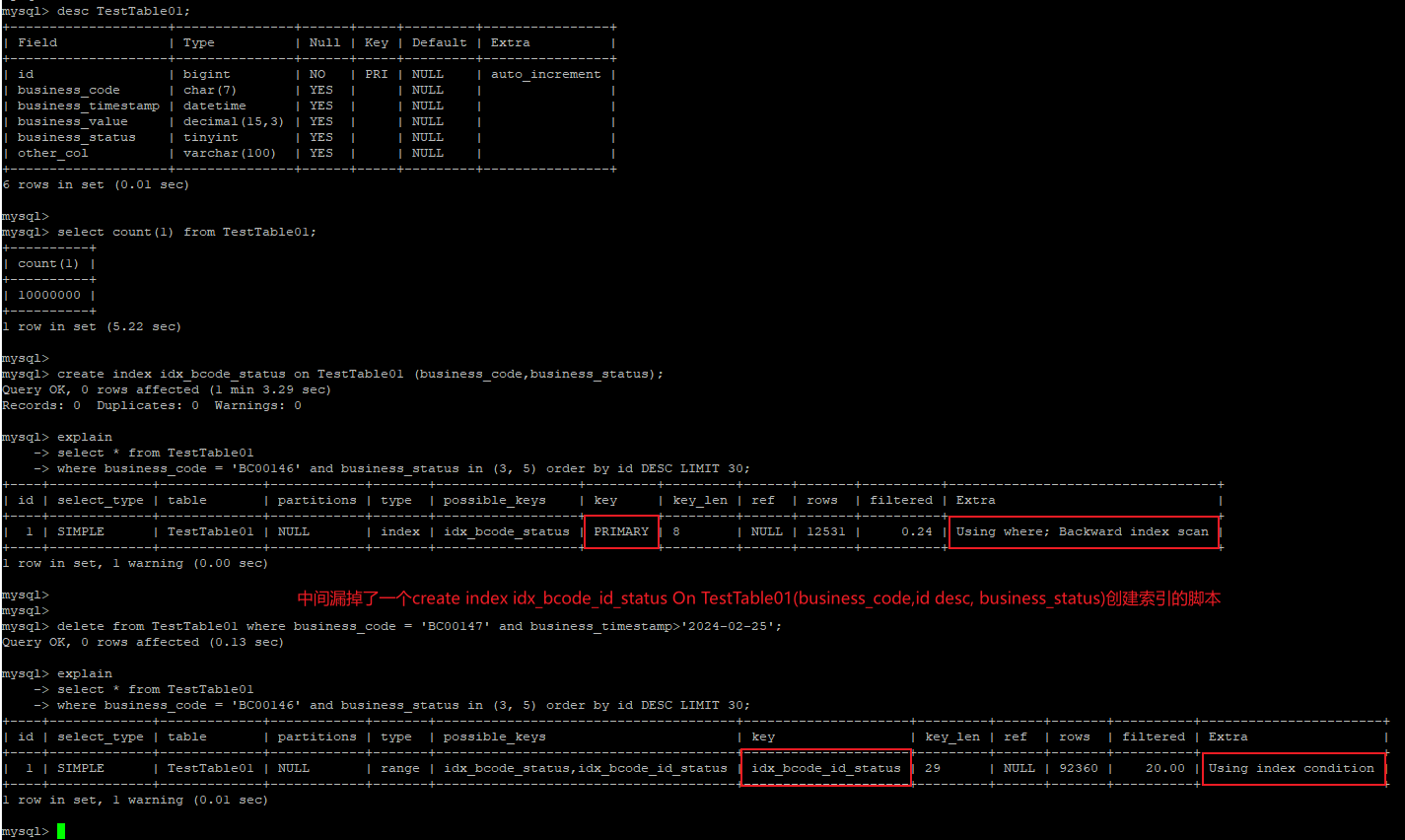
由上可見: 1,基于主鍵(聚集索引)的反向索引掃描,對(duì)于多數(shù)case沒有問題,但是對(duì)于特殊case會(huì)造成巨大的IO消耗,并不是一個(gè)最優(yōu)解。 2,對(duì)于常規(guī)的基于where條件的索引,優(yōu)化器壓根就不會(huì)選擇它。 如何建立索引上文一開始就提到了,對(duì)于常規(guī)的case,優(yōu)化器默認(rèn)的反向聚集索引掃描已經(jīng)是一個(gè)最優(yōu)解了,基于where條件建立的索引(create index idx_bcode_statue on TestTable01 (business_code,business_status)),默認(rèn)情況下也用不上。但是對(duì)于非常規(guī)的case,比如上述BC147這種,某些業(yè)務(wù)代碼最近一段時(shí)間內(nèi)并沒有產(chǎn)生業(yè)務(wù)數(shù)據(jù),再用默認(rèn)的反向聚集索引掃描就不合理了,因?yàn)檫@個(gè)掃描會(huì)掃描出來一大批數(shù)據(jù)頁面,才能找到滿足條件的數(shù)據(jù),因此這是一個(gè)不合理的執(zhí)行計(jì)劃。但同時(shí),代碼層面無法判斷某個(gè)業(yè)務(wù)代碼在近期否產(chǎn)生了業(yè)務(wù)數(shù)據(jù),也就無從得知那個(gè)參數(shù)使用默認(rèn)的聚集索引掃描更高效。因此需要一種對(duì)于兩種case都適用的優(yōu)化方式,既然按照id做倒序排序查詢某個(gè)業(yè)務(wù)代碼的數(shù)據(jù),那可以直接基于業(yè)務(wù)代碼和“倒序”Id的聯(lián)合索引 直接上代碼
create index idx_bcode_id_status on TestTable01(business_code, id desc, business_status)
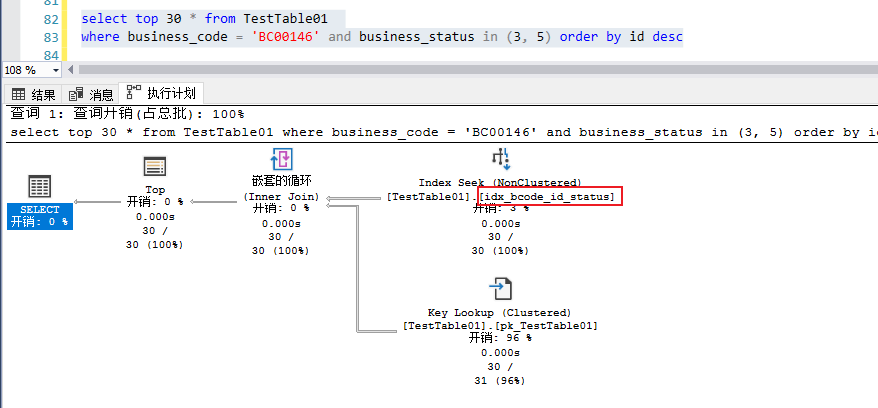
基于上面idx_bcode_id_status 創(chuàng)建之后的執(zhí)行計(jì)劃如下:
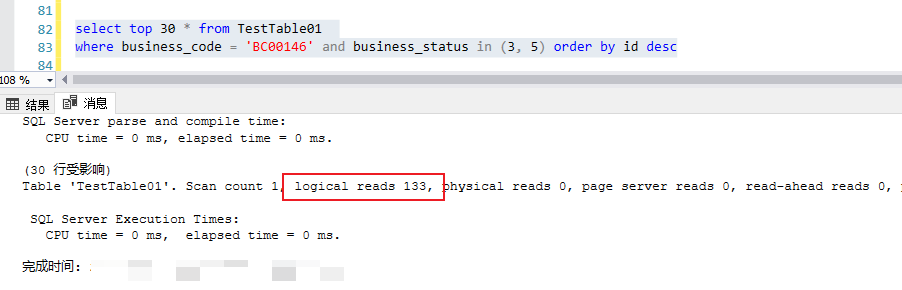
對(duì)于數(shù)據(jù)分布均勻的case
對(duì)于基于時(shí)間戳最近沒有生成數(shù)據(jù)的case,一樣都會(huì)基于idx_bcode_id_status 這個(gè)索引做index seek
該索引的思路就是,基于business_code,然后加上自增Id的倒序方式,讓business_code的數(shù)據(jù)按照Id倒序的方式組織索引,其查詢的過程中會(huì)先掃描出來最新的數(shù)據(jù)頁。
反向索引優(yōu)化是否適合于MySQL同時(shí),該場景問題的優(yōu)化,不但可以應(yīng)用在SQLServer上,索引的原理是一樣的,在MySQL上頁同樣適用,MySQL早期版本不支持倒序索引,但是語法不報(bào)錯(cuò),MySQL 8.0之后是支持反向索引的,下面是在MySQL 8.0.36上測試的,效果類似于SQLserver中。
MySQL下測試代碼 create table TestTable01 ( id bigint AUTO_INCREMENT NOT NULL PRIMARY key, business_code char(7), business_timestamp datetime, business_value decimal(15,3), business_status tinyint, other_col varchar(100) ); SET GLOBAL innodb_flush_log_at_trx_commit = 0; SET GLOBAL sync_binlog = 0; -- 生成測試數(shù)據(jù)存儲(chǔ)過程 CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`() LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '' BEGIN -- start TRANSACTION; set loop_count = 0; while loop_count<10000000 do INSERT INTO TestTable01(business_code,business_timestamp,business_value,business_status,other_col) VALUES (CONCAT('SC',LPAD(cast(CAST(RAND()*200 AS UNSIGNED int) AS CHAR), 5, '0')),DATE_ADD('2024-01-01', INTERVAL loop_count second),RAND()*10000,CAST(RAND()*5 AS UNSIGNED INT),UUID()); SET loop_count = loop_count + 1; END while; -- COMMIT; END call create_test_data(1000000);
總結(jié) 針對(duì)查詢創(chuàng)建索引的時(shí)候,不但要看where條件中字段的選擇性,同時(shí)要關(guān)注排序條件,因?yàn)楹雎粤伺判驐l件的情況下,僅關(guān)注查詢where的篩選字段,如果直接用索引過濾出來數(shù)據(jù),再排序后返回?cái)?shù)據(jù),可能是一個(gè)非常消耗資源的操作,因此優(yōu)化器不選擇這些索引也很正常,如果能夠通過索引建立與查詢語句排序一致的索引,才能適應(yīng)于此類查詢。 轉(zhuǎn)自https://www.cnblogs.com/wy123/p/18229506 該文章在 2025/2/17 16:38:06 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲(chǔ)管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")